Linux Kernel 中的数据结构——泛型 LinkedList
这是系列文章 「Linux Kernel 中的数据结构」的第一篇,欢迎关注
众所周知,Linux Kernel 是用 C 写的,但是 C 语言并没有像 Java 那样原生支持 Generic Programming,那要如何用 C 实现泛型数据结构呢?
了解 C 的同学这时候会喊,可以用 void pointer 啊
/* A doubly linked list node */
struct Node
{
// Any data type can be stored in this node
void *data;
struct Node *prev;
struct Node *next;
};
void 指针可以指向任何数据类型,就像 Java 中的 Object 类一样。这样不仅可以实现泛型链表,甚至允许一个链表可以存储多种类型的数据。
Kernel 中的 Linked List
但 Kernel 中没有这么做。与之相反,它的做法是在数据的 struct 里嵌入一个 Linked List 的 node. 这种不包含数据的 Linked List 的专业术语叫 Intrusive Linked List,它使得 list 相关的操作不用关心数据的类型,从而达到泛型的目的。
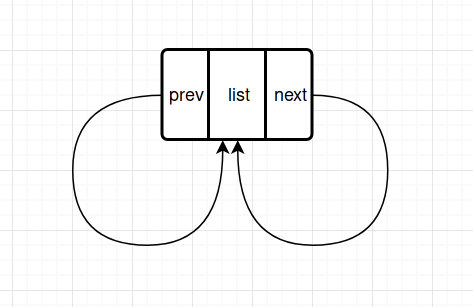
Node 节点只包含 prev 和 next 指针
/* https://github.com/torvalds/linux/blob/3724921396dd1a07c93e3516b8d7c9ff570d17a9/include/linux/types.h#L181 */
struct list_head {
struct list_head *next, *prev;
};
比如,Linux 网络栈最重要的数据结构 sk_buff 就嵌入了 list_head(由于 sk_buff 承担了很多职责,非常复杂,union 中的其它项不管)
/* https://github.com/torvalds/linux/blob/75a56758d6390ea6db523ad26ce378f34b907b0c/include/linux/skbuff.h#L690 */
struct sk_buff {
union {
struct {
struct sk_buff *next;
struct sk_buff *prev;
...
};
struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack*/
struct list_head list;
};
...
}
可以通过 sk_buff->list.prev 访问前一个 sk_buff,sk_buff->list.next 访问下一个 sk_buff
List 相关的操作
Init
list 的变量有两种初始化方式,一种是在 stack 中初始化,函数调用结束后会自动销毁;另外一种是在 heap 中初始化,需要自己手动 malloc 和 free. 注意初始化的 head 不含数据,是一个 dummy 指针。
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L21 */
/*
* 在 stack 中初始化
* 宏展开之后就是 struct list_head name = { &(name), &(name) };
* 分成两步来看
* struct list_head name; // stack 上已经分配好了内存地址
* name = { &(name), &(name) }; // 因此可以取 name 的地址,并赋值给 name
*/
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
/*
* 在 heap 中初始化
* WRITE_ONCE 大概就是防止 compiler 做指令合并、重排的优化,感兴趣的可以自己研究一下
* 这里就看成 list->next = list;
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
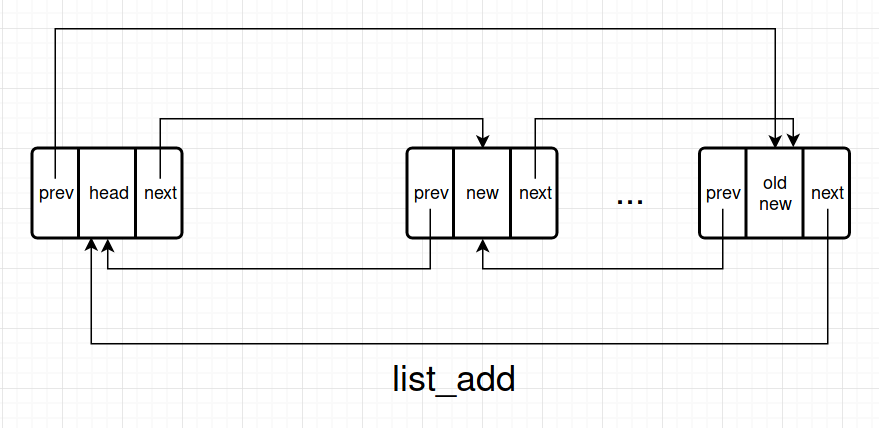
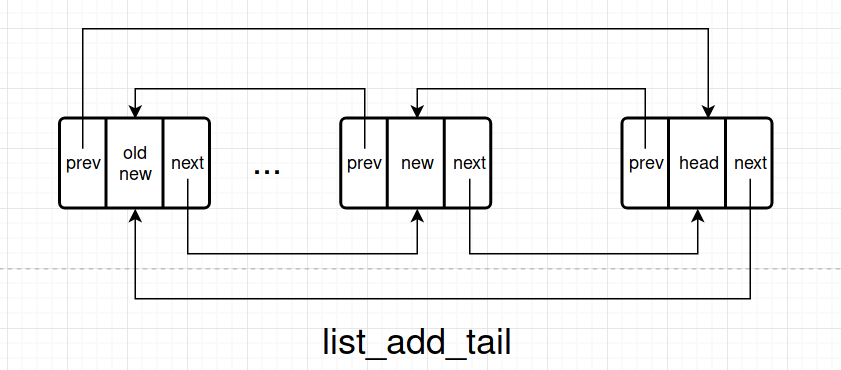
Add
add 操作有两种
list_add, 它把 new_entry 插入到 head 的后面list_add_tail,它把 new_entry 插入到 head 的前面
它们都调用 __list_add。由于 head->next 是 list 的第一个元素,因此 list_add 实现了数据结构中的 stack, 而 list_add_tail 实现了 queue.
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L77 */
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L91 */
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L56 */
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
Get Entry
del, replace, move, is_empty, rotate, cut, splice 只是一些指针操作,就不罗列了。现在来看看怎么从 list 中获取到 entry 的数据
假设我们已经做了以下操作,初始化了一个 skb_queue,并把一个 skb 中的 list 添加进了这个 queue. 注意这里并没有把 skb 加进去。
struct list_head skb_queue;
INIT_LIST_HEAD(&skb_queue);
list_add_tail(&skb->list, &skb_queue)
现在我想从这个 list 中取出这个(第一个) skb,获取 skb 内部的数据。
skb = list_first_entry(&skb_queue, struct sk_buff, list)
来看看 list_first_entry 的实现. ptr 就是 skb_queue 的指针;由于我们是在 sk_buff 嵌入了 list_head,所以 type 是 struct sk_buff; 这个 list_head 在 sk_buff 叫 list, 所以 member 是 list.
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L489 */
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
skb_queue 的第一个元素就是 ptr->next,再用 list_entry 获取相应的 entry, 最后是用 container_of
/* https://github.com/torvalds/linux/blob/8f9fab480c7a87b10bb5440b5555f370272a5d59/include/linux/kernel.h#L969 */
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \
!__same_type(*(ptr), void), \
"pointer type mismatch in container_of()"); \
((type *)(__mptr - offsetof(type, member))); })
这里 BUILD_BUG_ON_MSG 只是确保类型一致,不管。ptr 类型是 struct list_head *, type 是 struct sk_buff, member 是 list. 我们知道一个 struct 分配的内存是连续的,这里我们有 sk_buff 中 list 的地址值 ptr,只要减去 list 的位移,就能得到整个 sk_buff 的地址,然后再转换成 struct sk_buff *, 这样就拿到了 sk_buff.
这里我不是很理解为什么要转换成 void *, 转成 char * 应该更好, 因为按照 C 语言的标准,void 指针是不能做算术运算的,但 gcc 的实现支持了 void * 的算术运算。
Iterator
通过 container_of,我们能够从一个 struct list_head 获得嵌入它的宿主 struct. 在此基础之上,加入 iterator 支持也很简单。
/* https://github.com/torvalds/linux/blob/c8af5cd75e2411d5a5aacf115f59a5ff6b87f3fa/include/linux/list.h#L663 */
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
&pos->member != (head); \
pos = n, n = list_next_entry(n, member))
list_for_each_entry_safe 是这样使用的
/* https://github.com/torvalds/linux/blob/6413139dfc641aaaa30580b59696a5f7ea274194/net/core/dev.c#L5208 */
static void netif_receive_skb_list_internal(struct list_head *head)
{
struct sk_buff *skb, *next;
struct list_head sublist;
INIT_LIST_HEAD(&sublist);
list_for_each_entry_safe(skb, next, head, list) {
net_timestamp_check(netdev_tstamp_prequeue, skb);
skb_list_del_init(skb);
if (!skb_defer_rx_timestamp(skb))
list_add_tail(&skb->list, &sublist);
}
...
}
熟悉 Java 的同学都知道不能在 forEach 中删除元素。这里也是要删除元素, skb_list_del_init, 所以使用了 list_for_each_entry_safe. skb 是当前 entry, next 是下一个 entry. skb_list_del_init 清除当前 skb 的指针,但接下来又把 next 赋值给了 skb, 所以是删除安全的。
对比
void 指针和 Intrusive Linked List 各有优缺点。从 Intrusive Linked List 角度来看。
Pros
- 只需要一次 malloc 就能分配内存;而 void pointer 需要两次,一次是分配 data,还有一次是分配 node 节点。
- 能直接定位到在 list 中的位置,比如 sk_buff->list 就能得到 prev 和 next 指针,因此可以快速操作指针;而 void pointer 方式中的 data 没有到 list 位置的映射
- 更安全,因为 void pointer 太自由了
Cons
- 具有侵入性,需要修改目标 struct,比如在 sk_buff 加入 list_head
- 每一个 node 节点只能是同一种类型,而 void pointer 可以指向不同的数据类型
总结
C 不具备泛型原语,但仍有方法达到泛型的目的;就像 C 不具备 OOP 原语,但同样能用 struct 达到封装,用 function pointer 达到多态的目的。