聊一聊古老的 x-www-form-urlencoded
在为一个服务写 API 接口, 它是这样子发数据的
HTTP发布接口以POST表单的方式将数据发送到用户服务器,Content-Type 为application/x-www-form-urlencoded; HTTP request body 格式形如 a=b&c=d
第一反应, “这是啥, 为什么不用 json?"。抱怨归抱怨,事情还是要做的。举个例子:
针对这样的数据
{
"title": "t",
"author": "a"
}
会以这样的形式发送到服务器:
https://host/path/to/api?title=t&author=a
看上去没什么问题,so easy.
但如果数据是这样子呢? 里面含有 list
{
"title": "t",
"author": "a",
"categories": ["c1", "c2"]
}
怎么处理 categories 这种 list 类型?
这样?
# Percent-encoding 之前
https://host/path/to/api?title=t&author=a&categories=["c1", "c2"]
注意, 其实在 url 中,一些字符会进行 Percent-encoding 处理,再发送给服务端。
# percent-encoding 之后
https://host/path/to/api?title=t&author=a&categories=%5B%22c1%22,%20%22c2%22%5D
还是其它什么形式?我把能想到的都尝试了一次,但都无果。我用的 python web 框架 Flask 的文档又那么糟糕,难受。
源码
Code Ninja 曾说过,“看不透的话,就看源码吧!源码是最真实的”。
谨遵大师教诲,我翻了一下 python 上的 Flask 源码(对应的 url decode 代码)。
def url_decode_stream(stream, charset='utf-8', decode_keys=False,
include_empty=True, errors='replace', separator='&',
cls=None, limit=None, return_iterator=False):
from werkzeug.wsgi import make_chunk_iter
if return_iterator:
cls = lambda x: x
elif cls is None:
cls = MultiDict
pair_iter = make_chunk_iter(stream, separator, limit)
return cls(_url_decode_impl(pair_iter, charset, decode_keys,
include_empty, errors))
return_iterator 默认是 false, 那么 cls 默认就是 MultiDict。把 _url_decode_impl 的结果喂给 MultiDict. MultiDict 是个什么东西?从名字上可以猜测一下,Dict 就是 Key-value pairs, 一个 key 对应一个 value. 那么 Multi 是什么? 是指一个 key 可以有多个 value 吗?
`MultiDict` is a dictionary subclass customized to deal with
multiple values for the same key which is for example used by the parsing
functions in the wrappers. This is necessary because some HTML form
elements pass multiple values for the same key.
:class:`MultiDict` implements all standard dictionary methods.
Internally, it saves all values for a key as a list, but the standard dict
access methods will only return the first value for a key. If you want to
gain access to the other values, too, you have to use the `list` methods as
explained below.
Basic Usage:
>>> d = MultiDict([('a', 'b'), ('a', 'c')])
>>> d
MultiDict([('a', 'b'), ('a', 'c')])
>>> d['a']
'b'
>>> d.getlist('a')
['b', 'c']
还真是如此。MultiDict 中一个 key 可以有多个 value 。dict[key] 默认取第一个 value, dict.getlist(key) 可以得到所有的 value. 而且还特意强调了 “This is necessary because some HTML form elements pass multiple values for the same key”, 感觉 MultiDict 就是为 form 而生的,哈哈。
那么 _url_decode_impl 是怎样的? 它有一个参数是 pair_iter, pair_iter 是从请求中的 querystring(这里就是 title=t&author=a)解析出来的[‘title=t’, ‘author=a’] 这样的 list。我们看看 _url_decode_impl 是怎么处理这个 list 的
def _url_decode_impl(pair_iter, charset, decode_keys, include_empty, errors):
for pair in pair_iter:
if not pair:
continue
s = make_literal_wrapper(pair)
equal = s('=')
if equal in pair:
key, value = pair.split(equal, 1)
else:
if not include_empty:
continue
key = pair
value = s('')
key = url_unquote_plus(key, charset, errors)
if charset is not None and PY2 and not decode_keys:
key = try_coerce_native(key)
yield key, url_unquote_plus(value, charset, errors)
很简单, 就是 split 一下,然后对 value 进行一下一些编码上的处理。有 yield 的函数是一个 generator, 调用方(这里是 MultiDict 构造函数里的 iterator) 每次要 nextValue 的时候, 生成一个中间值(这里是 key, value 的 tuple),抛给调用方。
小结一下, 根据 querystring 得到一个 list, 然后用这个 list 构造 MultiDict. MultiDict 允许一个 key 有多个 value.
回到我们最初的问题
{
"title": "t",
"author": "a",
"categories": ["c1", "c2"]
}
就需要以这样的请求发送到服务器:
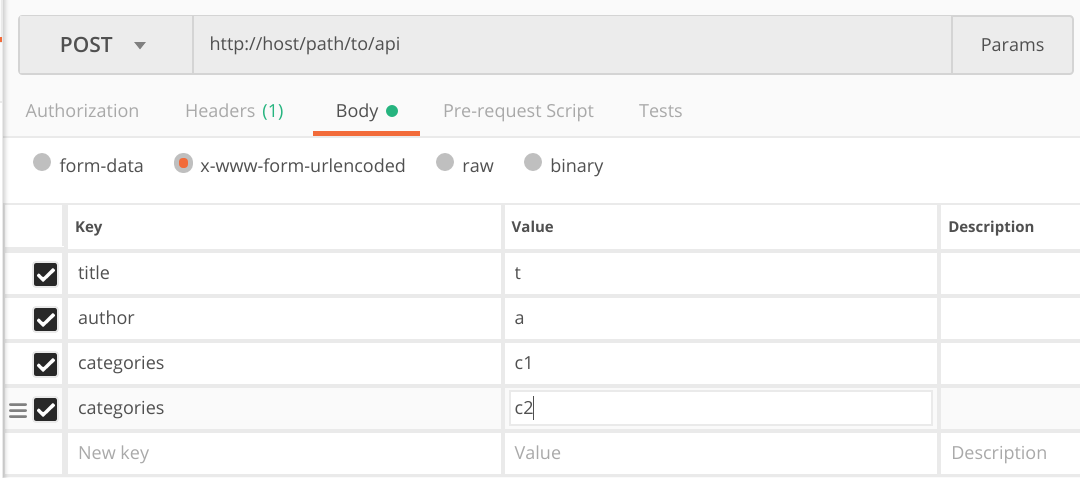
https://host/path/to/api?title=t&author=a&categories=c1&categories=c2
使用 Postman 等模拟 API 请求的工具时,就会是这样:
等等,这个只是 python 中的 Flask 实现,万一其它的 web frameworks 不是这样处理的,怎么办?万一 Flask 的作者放飞了自我,写了一个不一样的烟火, 怎么办?
别着急,走过路过不要错过 Spring Framework 的实现。
private MultiValueMap<String, String> parseFormData(Charset charset, String body) {
String[] pairs = StringUtils.tokenizeToStringArray(body, "&");
MultiValueMap<String, String> result = new LinkedMultiValueMap<>(pairs.length);
try {
for (String pair : pairs) {
int idx = pair.indexOf('=');
if (idx == -1) {
result.add(URLDecoder.decode(pair, charset.name()), null);
}
else {
String name = URLDecoder.decode(pair.substring(0, idx), charset.name());
String value = URLDecoder.decode(pair.substring(idx + 1), charset.name());
result.add(name, value);
}
}
}
catch (UnsupportedEncodingException ex) {
throw new IllegalStateException(ex);
}
return result;
}
MultiValueMap 和 python 中的 MultiDict 是一样的,允许一个 key 有多个 value. 可以看出,本质上和 Flask 中的处理是一样的。看来这些 framework 的作者是相通(互相借鉴)的。
标准
可我还是不能确定,web framework 千千万万, 我们怎么能确定所有的 web framworks 都是这样处理 x-www-form-urlencoded 的呢。
Code Ninja 又发话了,“如果单一的实现不能让你满足,那么就去看标准 (Specification) 吧。跟着标准走,不会吃亏。
看,这是标准
先来看看标准里对 x-www-form-urlencoded 的评价
The application/x-www-form-urlencoded format is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices. In particular, readers are cautioned to pay close attention to the twisted details involving repeated (and in some cases nested) conversions between character encodings and byte sequences. Unfortunately the format is in widespread use due to the prevalence of HTML forms.
心疼 x-www-form-urlencoded 一秒钟。
标准中对 application/x-www-form-urlencoded parsing 的描述
The application/x-www-form-urlencoded parser takes a byte sequence input, and then runs these steps:
Let sequences be the result of splitting input on 0x26 (&).
Let output be an initially empty list of name-value tuples where both name and value hold a string.
For each byte sequence bytes in sequences:
If bytes is the empty byte sequence, then continue.
If bytes contains a 0x3D (=), then let name be the bytes from the start of bytes up to but excluding its first 0x3D (=), and let value be the bytes, if any, after the first 0x3D (=) up to the end of bytes. If 0x3D (=) is the first byte, then name will be the empty byte sequence. If it is the last, then value will be the empty byte sequence.
Otherwise, let name have the value of bytes and let value be the empty byte sequence.
Replace any 0x2B (+) in name and value with 0x20 (SP).
Let nameString and valueString be the result of running UTF-8 decode without BOM on the percent decoding of name and value, respectively.
Append (nameString, valueString) to output.
Return output.
其实是一样的,正因为有标准的存在,所有的 framework 都殊途同归。作为开发者,要感谢为标准做出贡献的人。
感慨
这是我第一次从一个小问题,追踪到源码,最后再看标准规定。整个过程很短,45分钟在找源码、看源码,一个半小时在找标准、读标准上。感觉挺爽的,很有成就感,特写此文记录一下,希望之后有更多的机会参与这样的探索。当然,如果哪天我能参与标准的制定过程中,那么我在技术上的追求也就圆满了。
参考
- python 的源码位于 https://github.com/pallets/werkzeug/blob/0.14.1/werkzeug/urls.py#L737:5
- spring 的源码位于 https://github.com/spring-projects/spring-framework/blob/356bfe6e2ec38fdf2d8a85c4d5cef8cfd386d5db/spring-web/src/main/java/org/springframework/http/codec/FormHttpMessageReader.java#L117:10
- Url Standard 位于 https://url.spec.whatwg.org/#application/x-www-form-urlencoded